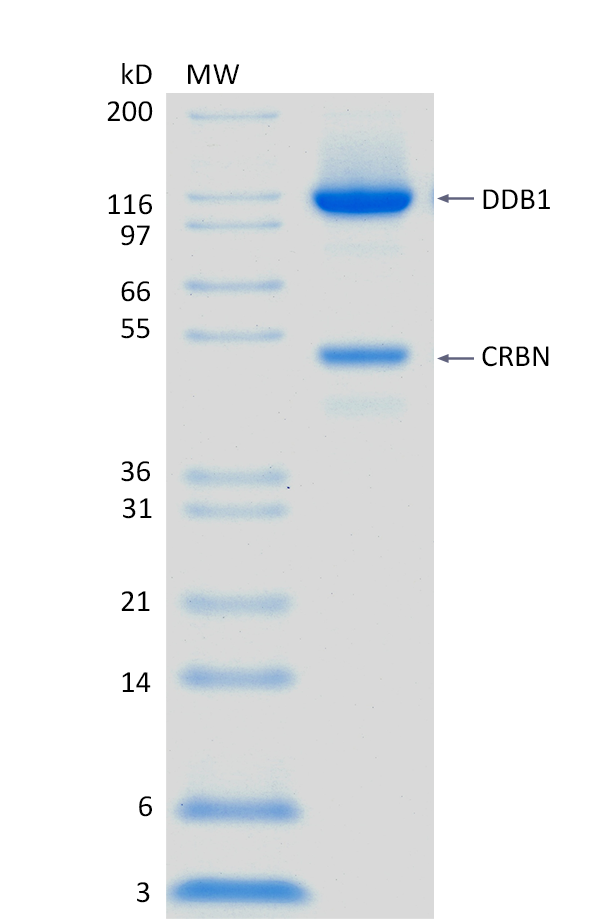
 2 μg CRBN/DDB1 run on 4-12% SDS-PAGE gel under reducing conditions, then visualized with Colloidal Coomassie Blue Stain.
2 μg CRBN/DDB1 run on 4-12% SDS-PAGE gel under reducing conditions, then visualized with Colloidal Coomassie Blue Stain.For Research Use Only (RUO)
Carter T.R., et al. (2024) Bioorg Med Chem. 104: 117699. PMID 38608634
Costacurta M., et al. (2024) FEBS J. 291 (22): 4892-4912 PMID 38975872
Federspiel J.D., et al. (2024) Mol Cell Proteomics 23 (7): 100797 PMID 38866076
Kroupova A., et al. (2024) Nat Commun. 15: 8885. PMID 39406745